Dataflows
Filter and sort
The category Filter and sort in the dataflow step selection holds every step that narrows down and orders the rows of your table: filter by conditions, sort by columns, filter by date and time values or remove duplicates. To learn how to create a dataflow and add steps in general, see the first steps with dataflows.
Filter
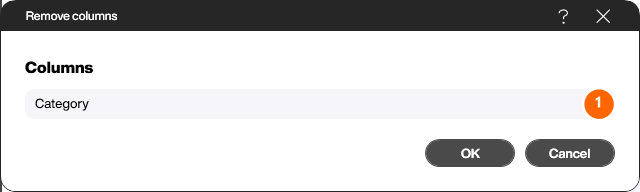
With this step you filter the table based on one or more conditions. Use [Add first filter] to pick the column to check (1), then choose the operator (2) and enter the comparison value (3). Use [Add AND condition] and [Add OR block] to combine several conditions. For more complex logic, switch to the script editor with [Use script editor] (4) and define the filter logic in a script.
For example, if you get warehouse transaction data from a previous system for two warehouse areas, but you want to consider both areas separately (for example, with a utilization indicator for one and the other area), you create two dataflows and remove the data of the other area right at the beginning using a filter. This way you turn a mixed data source into two separate ones.
Sort
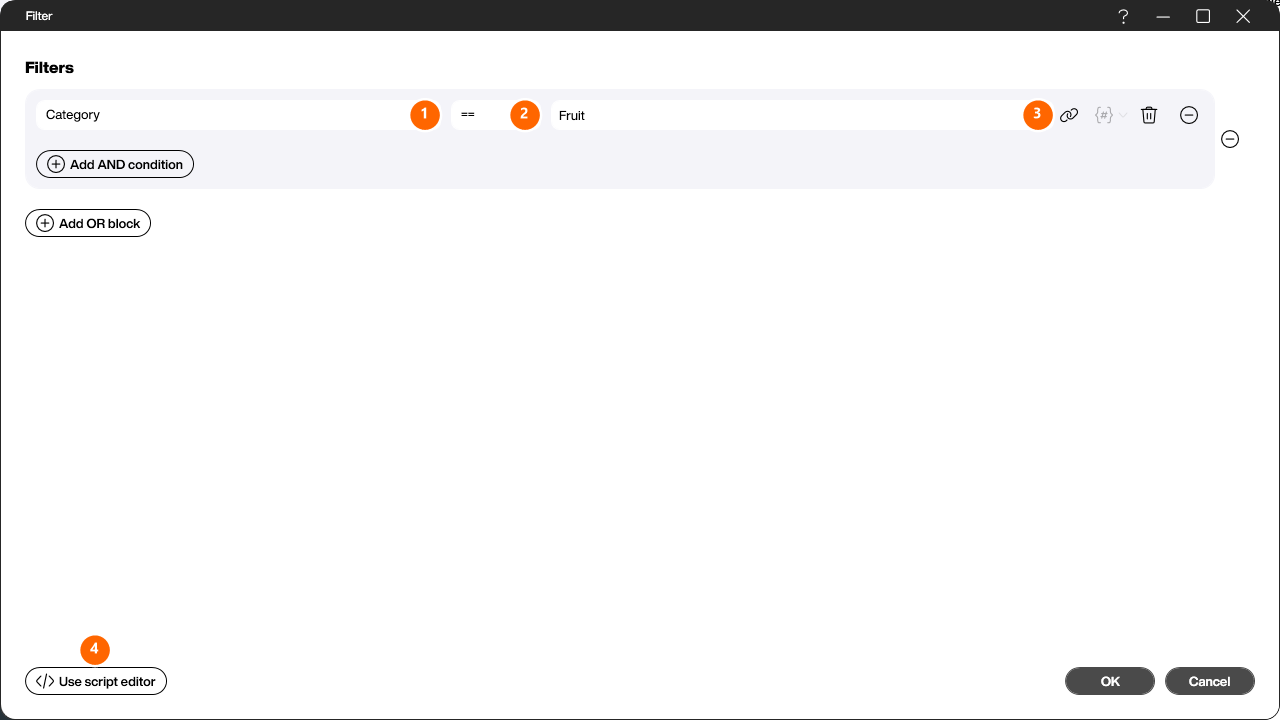
With this step you sort the table by one or more columns. In the [Columns] list (1), tick the columns you want to sort by. Each selected column appears in the [Column sort order] area, where you choose between [Ascending] and [Descending] with the selector (2). You change the order of several sort columns by drag and drop.
Filter by date/time columns
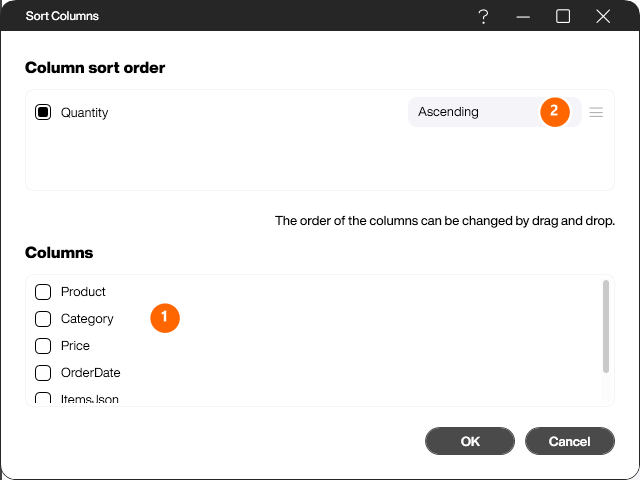
With this step you filter the table by date or time values. Pick the [Date/time column] (1) you want to filter and specify in the [Input format] (2) the format the values are stored in as a string, so they are interpreted correctly. Then set the operator (3) and the comparison value (4) – this can be another column or a fixed value. With the [Ignore time] option (5) only the date part is considered, not the time. A requirement for this step is the column type string.
Remove duplicates
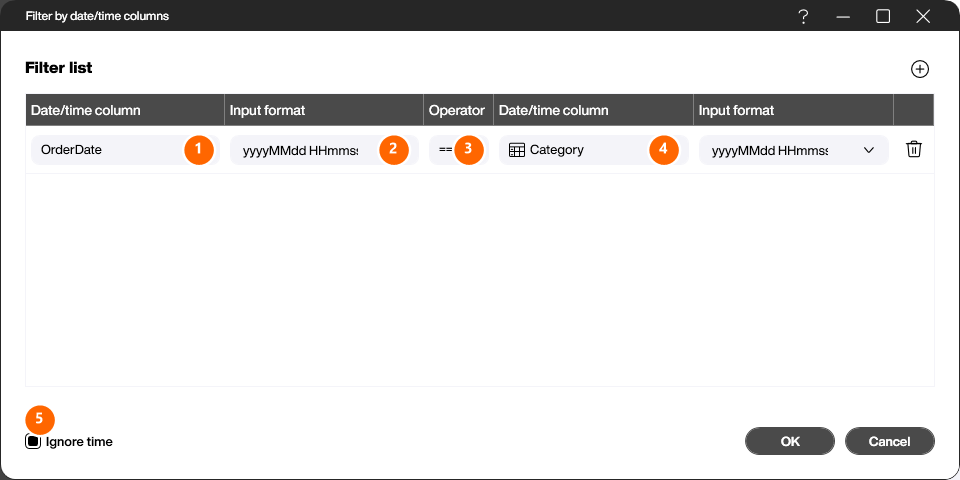
With this step you remove duplicates from the table. In the [Columns] field (1), pick the column used to detect duplicates. Of all rows that have an identical value in this column, only the first one is kept.