Data sources
Webpage
With the [Webpage table] data source you read an HTML table contained on a web page into Peakboard as a table (web scraping). For a general introduction on how to configure external data sources and bind them to controls, see the following tutorial:
Getting started with external data sources using an XML data source as an example.
Add the data source
Add the data source via a right click on [Data] and [Add data source]. Select the [Webpage table] tile (1) — you will find it in the [Web] category or through the search box.
If you don’t have a suitable web page at hand and just want to try things out, you can use the following example URL. It contains a large table with the population of every country:
https://www.worldometers.info/world-population/population-by-country/
Peakboard searches the web page for HTML tables. This works especially well if the HTML is syntactically correct. If the data on a web page is not recognized correctly or is incomplete, check the page’s HTML syntax.
Configure the connection and table
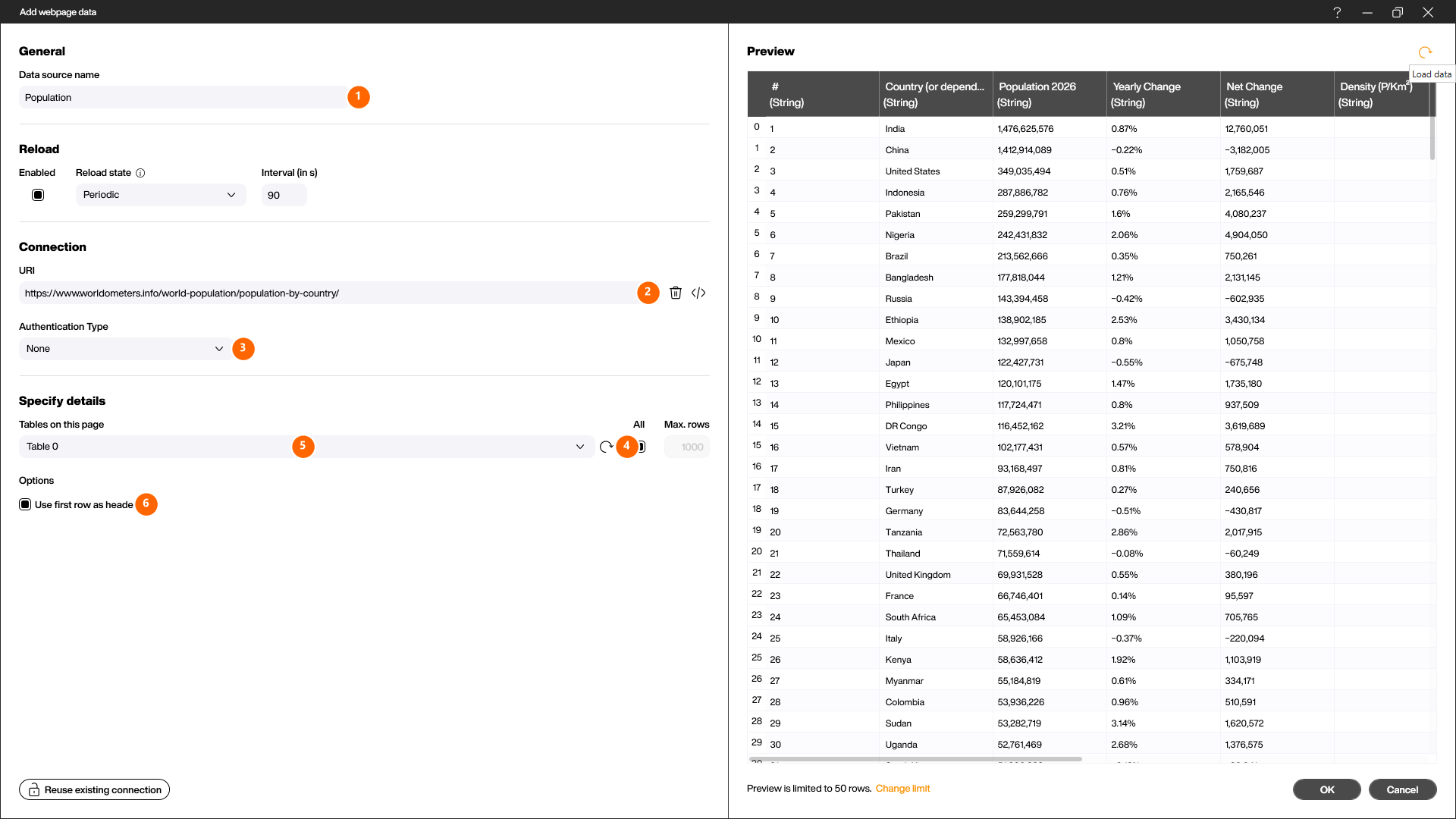
Give the data source a unique name (1) and enter the URL of the web page (2). If the web page requires authentication, choose the method in [Authentication Type] (3) — for the example URL this stays on [None].
A click on the load icon (4) makes Peakboard scan the page for HTML tables. Then pick the table you want in the [Table on this page] drop-down (5) — this example page contains only one table ([Table 0]).
If a table has no real HTML headers (<th> tag), the columns are named Column0, Column1, … and the actual captions sit in the first table row. In that case enable the [Use first row as header] checkbox (6) so the first row becomes the column headers. A click on [Load data] shows a preview of the selected table on the right — here the countries with their population. Confirm with [OK].
The metadata (columns and their data type) is copied. In the [Reload] section you can set the interval for automatically refreshing the data source in seconds and limit the maximum number of rows if needed. If the source changes for some reason, you can re-run the table detection at any time with the load icon.