Datenquellen
Flows
Funktion
Flows (früher Reload Flows) legen fest, wann und in welcher Reihenfolge Datenquellen und Dataflows nachgeladen werden. Das ist immer dann hilfreich, wenn eine Datenquelle oder ein Dataflow erst nach einer anderen Datenquelle geladen werden soll, oder wenn das Nachladen zeitgesteuert ablaufen muss.
Flows können für alle Pull-Datenquellen genutzt werden, für die ein Reload-Intervall festgelegt werden kann. Event-basierte Datenquellen wie MQTT oder OPC UA können nicht über einen Reload-Step nachgeladen werden, da sie ihren Aktualisierungszeitpunkt selbst bestimmen. Sie lassen sich aber als Trigger verwenden: Über den Trigger After data reload startet ein eingehendes MQTT-Event bzw. eine OPC-UA-Wertänderung den Flow.
Ein Flow besteht aus folgenden Bausteinen
| Trigger | Bestimmt, wann der Flow ausgeführt wird. Aktuell stehen vier Trigger zur Verfügung: Periodic (sec) für ein festes Sekundenintervall, Schedule für eine Zeitplanung mit Wochentagen und Uhrzeiten, After data reload, der einen Flow startet, sobald eine bestimmte Datenquelle neu geladen wurde, und After function execute, der den Flow startet, sobald eine bestimmte Funktion ausgeführt wurde. |
| Step | Ein Arbeitsschritt, der vom Flow ausgeführt wird. Der Step Reload lädt beliebige Datenquellen oder Dataflows nach. Der Step Run function führt eine zuvor im Paketexplorer angelegte Lua-Funktion aus – z.B. um Werte zu berechnen, Daten aufzubereiten oder Folgeaktionen anzustoßen. Steps werden in der gewählten Reihenfolge nacheinander abgearbeitet. |
| Failure function | Eine optionale Lua-Funktion, die ausgeführt wird, wenn ein Step im Flow fehlschlägt. So lassen sich z.B. Logmeldungen oder Benachrichtigungen umsetzen. |
Hinweis
Eine Datenquelle oder ein Dataflow kann in mehreren Flows verwendet werden. Achte darauf, durch mehrfache Nutzung keine versehentlichen Dauerschleifen zu erzeugen (z.B. wenn ein After data reload Trigger eine Datenquelle nachlädt, die wiederum den Trigger selbst auslöst).
Einen Flow erstellen
Um einen neuen Flow anzulegen, klickst du im Reiter [Start] des Peakboard Designers auf das Menü [Project] (1) und dort auf [Flows] (2).
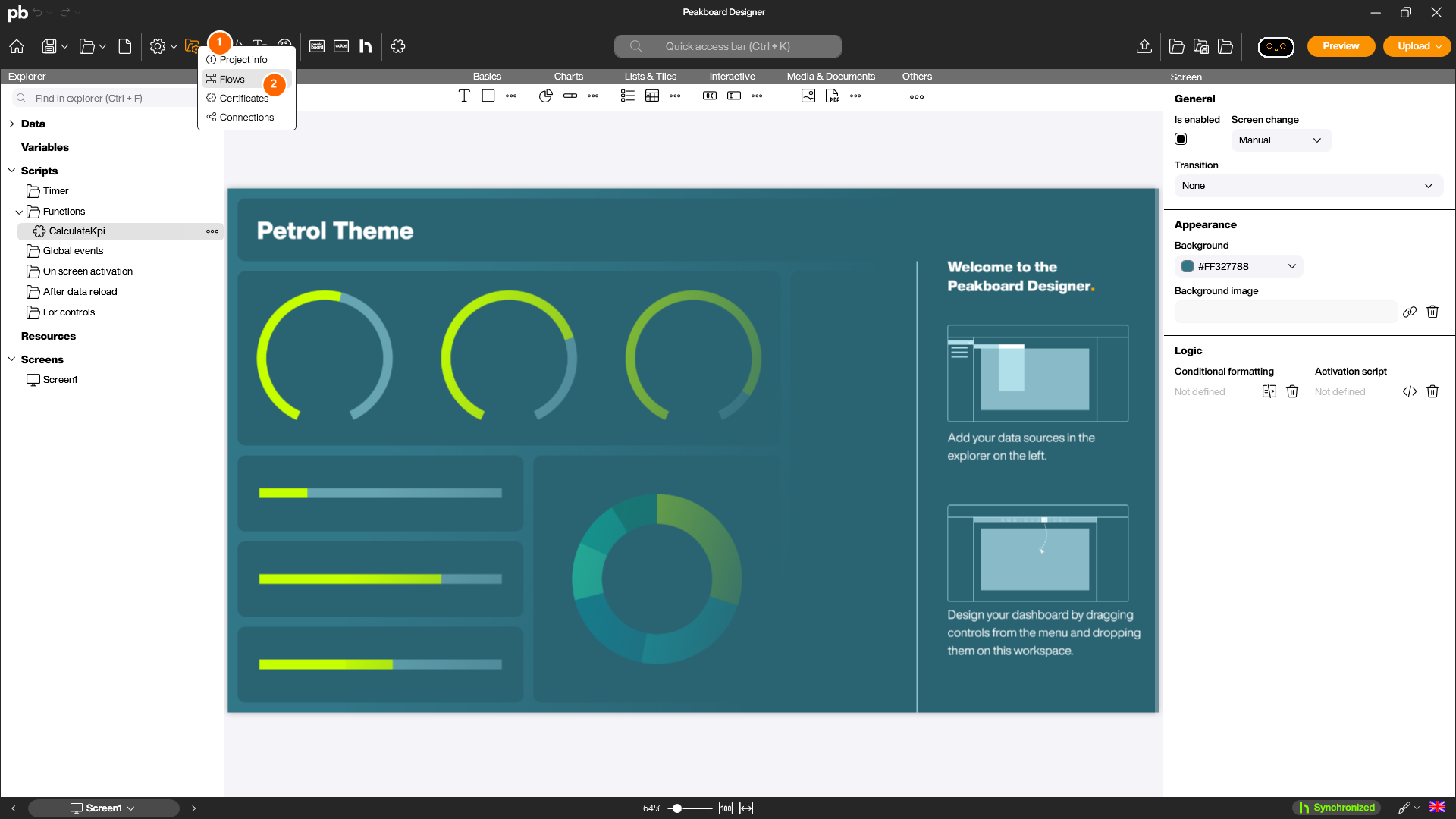
Solange noch keine Flows angelegt sind, zeigt der Dialog Manage flows einen leeren Zustand mit zwei Einstiegspunkten: dem [+] Icon in der linken Spalte (1) und der zentralen Schaltfläche [Add flow] (2). Beide öffnen den Editor für einen neuen Flow.
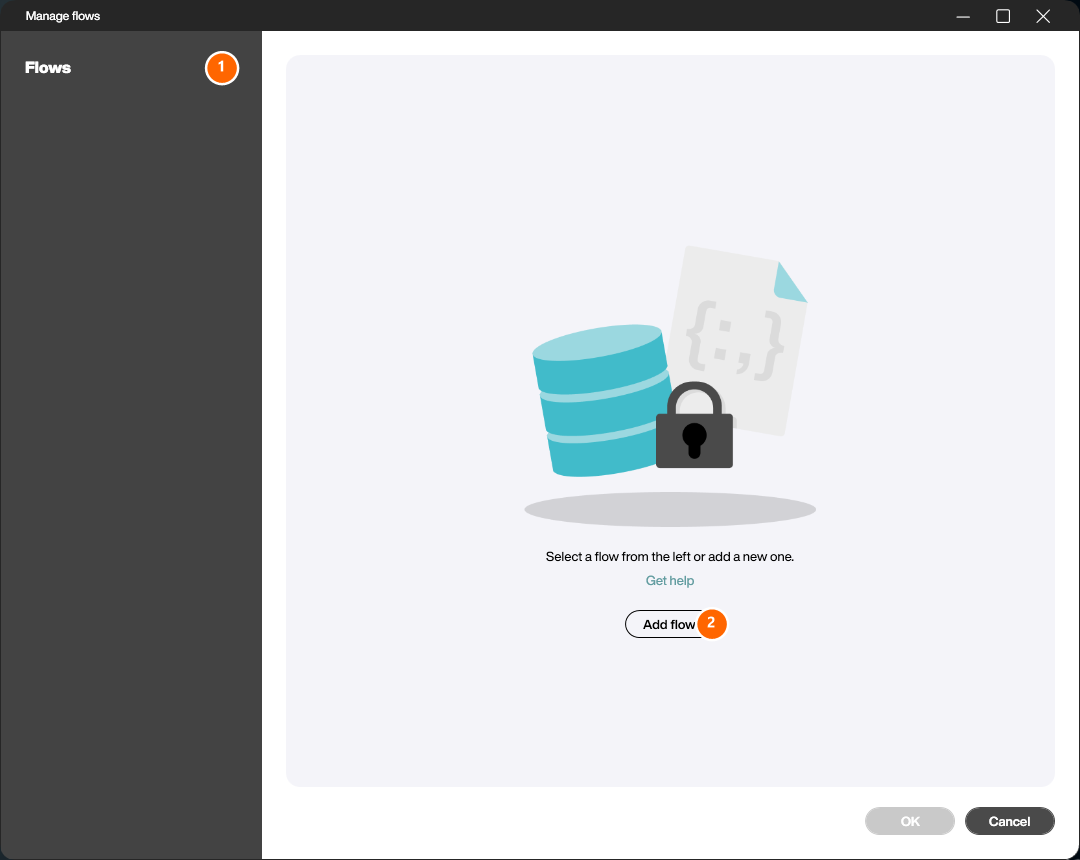
Den Flow konfigurieren
Im Editor vergibst du zunächst einen Namen für den Flow (1). Anschließend ziehst du per Drag-and-Drop aus dem rechten Bereich [Select triggers and steps] die gewünschten Bausteine in die jeweiligen Drop-Zonen im mittleren Bereich:
- Einen Trigger aus dem rechten Trigger-Picker (4) auf das gelb hervorgehobene Drop-Feld im Bereich Triggers (2). Im Beispiel wurde Periodic (sec) mit einem Intervall von 60 Sekunden konfiguriert. Ein Flow kann einen oder mehrere Trigger besitzen.
- Einen Step aus dem rechten Step-Picker (5) auf das Drop-Feld im Bereich Steps (3). Der Step Reload zeigt anschließend ein Drop-Down, in dem du die zu aktualisierende Datenquelle oder den Dataflow auswählst – im Beispiel die Datenquelle test.
Die Reihenfolge der Steps bestimmt die Ausführungsreihenfolge – sie kannst du jederzeit per Drag-and-Drop ändern. Einen Trigger oder Step entfernst du über das Mülleimer-Symbol am rechten Ende des jeweiligen Eintrags.
Hinweis
Wird kein Trigger gesetzt, läuft der Flow nur manuell – etwa wenn er aus einem Lua-Skript heraus aufgerufen wird (flows("MeinFlow"):run()).
Über [OK] werden alle Änderungen am Flow gespeichert, [Cancel] verwirft sie.
Datenquellen für Flows vorbereiten
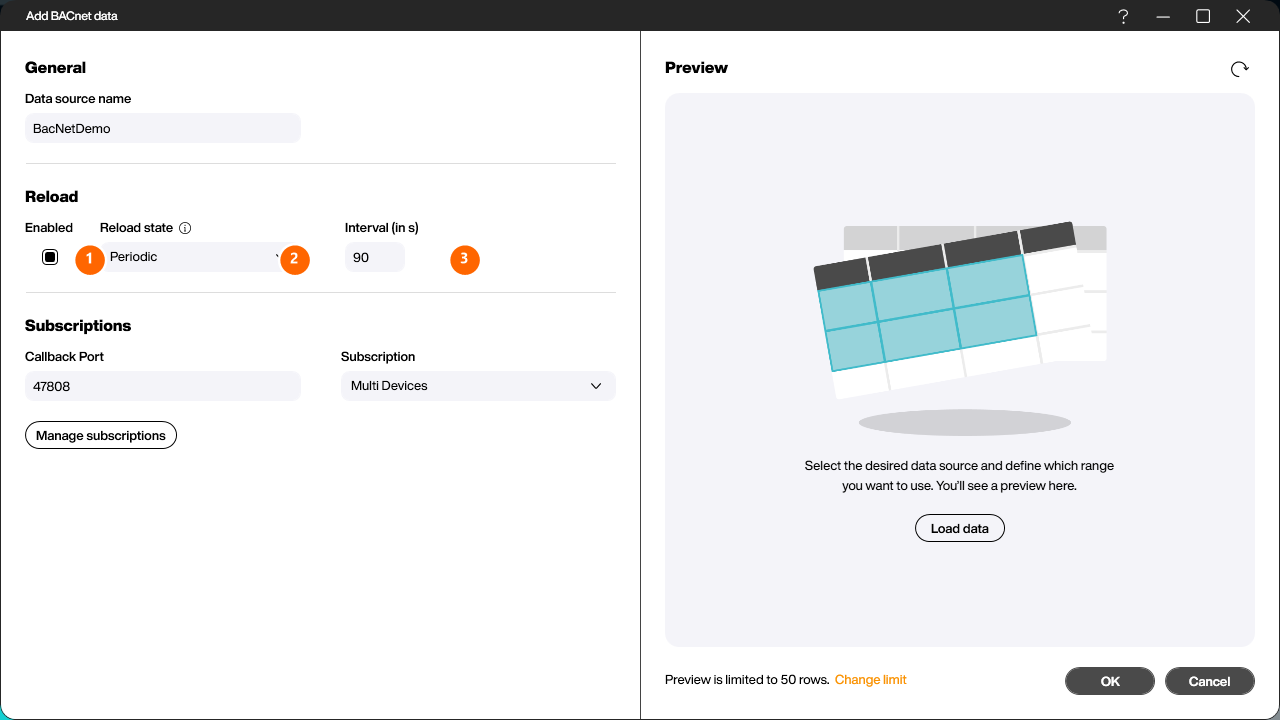
Damit eine Datenquelle von einem Flow nachgeladen werden kann, muss im Bereich Reload des Konfigurationsdialogs lediglich die Checkbox [Enabled] (1) aktiviert sein. Mehr ist nicht nötig: Sobald die Datenquelle in einem Reload-Step verwendet wird, bestimmt der Trigger des Flows, wann sie nachgeladen wird.
Der unter [Reload state] (2) gewählte Modus und das Feld [Interval (in s)] (3) steuern nur das eigenständige Nachladen der Datenquelle. Wird sie über einen Flow nachgeladen, übersteuert der Flow-Trigger dieses Intervall – eine hier eingestellte Periodik ist dann wirkungslos. In der Praxis genügt es daher, [Reload state] auf Manual zu stellen und das Timing vollständig dem Flow zu überlassen.
Funktionen im Flow ausführen
Neben Datenquellen kann ein Flow auch eigene Funktionen ausführen. Die Funktion muss dafür zuerst im Paketexplorer unter [Scripts] › [Functions] angelegt werden (1) – erst dann steht sie im Flow zur Verfügung.
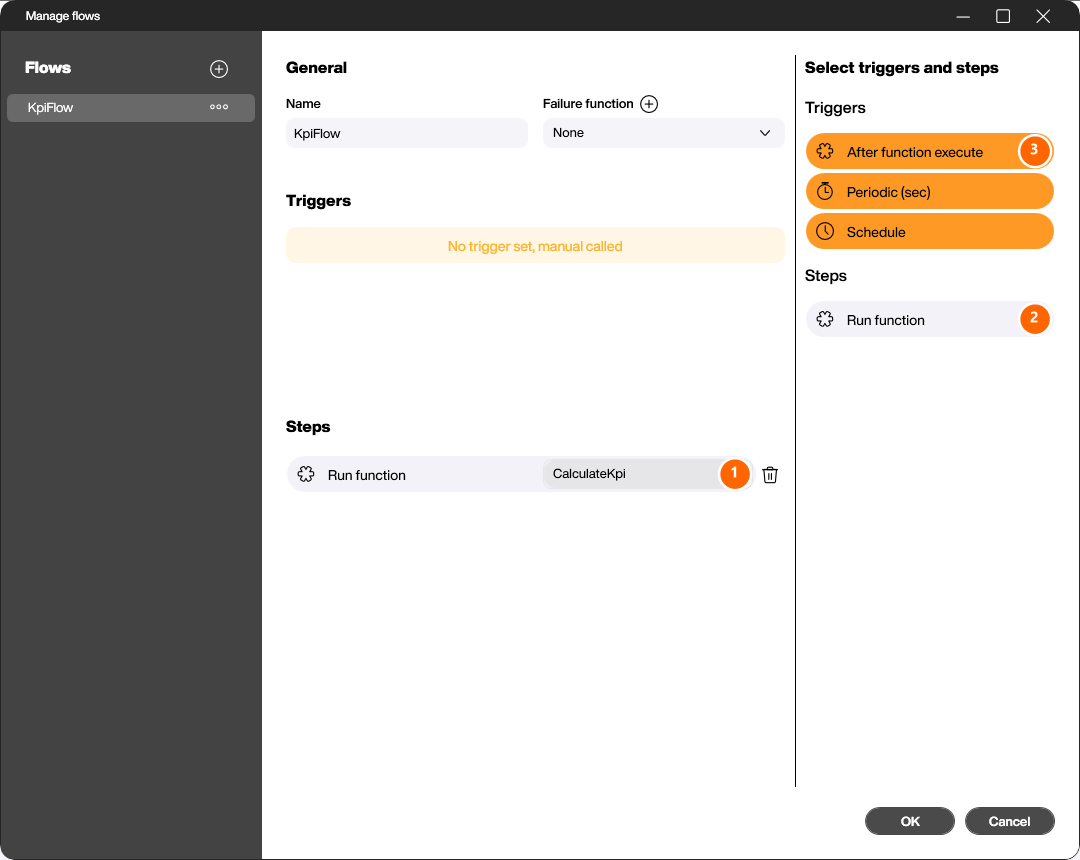
Anschließend ziehst du im Flow-Editor den Step Run function (2) aus dem rechten Step-Picker in den Bereich Steps und wählst im Drop-Down die gewünschte Funktion aus (1). Zusätzlich steht der Trigger After function execute (3) zur Verfügung, mit dem du einen Flow startest, sobald eine bestimmte Funktion ausgeführt wurde.
Bestehende Flows bearbeiten oder löschen
Im Dialog Manage flows wählst du in der linken Spalte den zu bearbeitenden Flow aus. Über das Drei-Punkte-Menü neben dem Flow-Namen kannst du den Flow umbenennen oder vollständig löschen. Trigger und Steps lassen sich entfernen, indem du mit der Maus über den jeweiligen Eintrag fährst und auf das Mülleimer-Symbol klickst, das dann sichtbar wird.
Tipp
Mit der optionalen Failure function kannst du eine Lua-Funktion hinterlegen, die bei einem Fehler in einem Step ausgeführt wird. Das eignet sich z.B. dafür, fehlgeschlagene Reloads in eine Protokoll-Datenquelle zu schreiben oder eine Push-Nachricht zu senden.